

先做个广告:如需代注册ChatGPT或充值 GPT4.0会员(plus),请添加站长微信:gptchongzhi
在过去的24小时内,我们有幸获得了 OpenAI 新发布的 o1-preview 和 o1-mini 模型的使用权限。这些模型经过特别训练,旨在模拟推理过程,并在给出最终答案之前给予更多时间生成和修正推理步骤。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
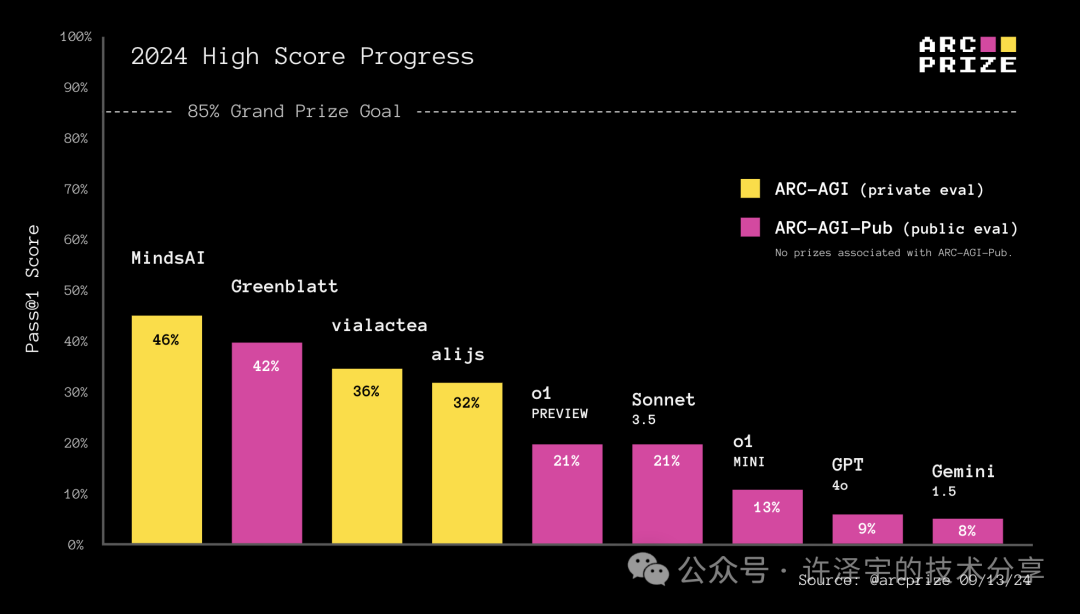
成百上千的人都在问,o1 在 ARC 奖项上的表现如何。因此,我们使用相同的基线测试工具对 o1 进行了测试,这些工具之前被用于评估 Claude 3.5 Sonnet、GPT-4o 和 Gemini 1.5。以下是测试结果:
究竟o1是否代表了一种通向AGI的新范式?它是否具备扩展性?如何解释o1在IOI、AIME等多个基准测试中的优异表现,却在ARC-AGI上成绩平平?
我们有很多内容需要探讨。
连锁推理
o1 完全实现了“逐步思考”的连锁推理(CoT)范式,并将其应用在训练和测试阶段。
OpenAI 在训练时使用了一种新型的强化学习(RL)算法和高效的数据处理流程,利用了连锁推理。
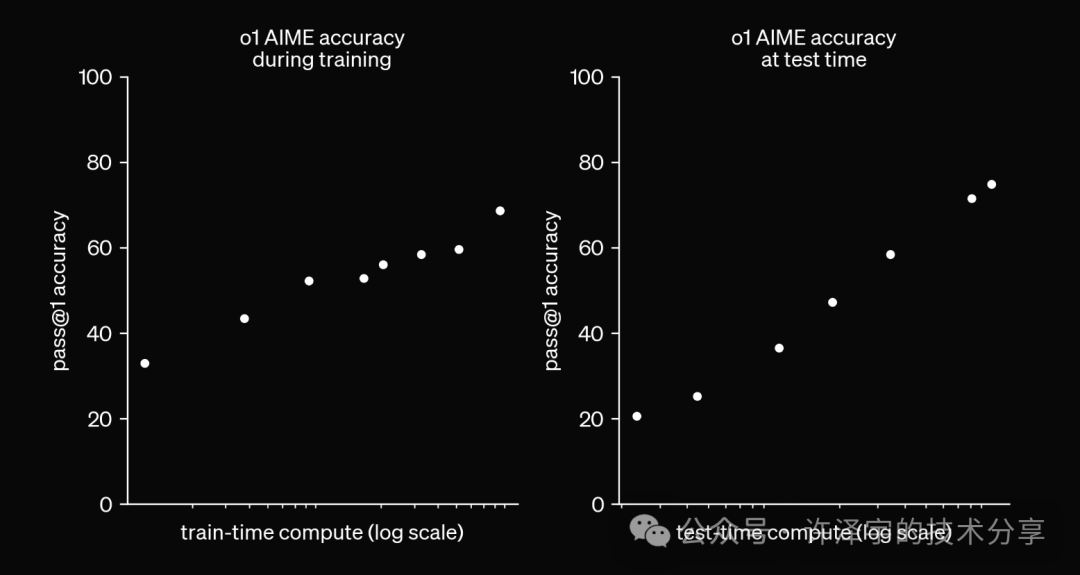
来源:OpenAI《通过 LLM 学习推理》
o1 训练的基础数据来源依然是固定的预训练数据集,但 OpenAI 能够生成大量模拟人类推理的合成连锁推理数据,用于进一步强化模型训练。一个悬而未决的问题是,OpenAI 如何选择哪些生成的连锁推理数据进行训练?
在具体实践中,o1 在处理那些在合成连锁推理训练数据中有良好表示的中间步骤序列时,显著减少了犯错的概率。
虽然我们缺乏详细信息,但推测 RL 的奖励信号可能通过验证(如数学和编程领域的形式化验证)和人工标注(如任务分解和计划领域的非形式化标注)实现。
在推理时,OpenAI 表示他们使用了RL来优化o1的连锁推理,并改进其使用的策略。可以推测的是,奖励信号可能来自于类似于OpenAI以前发布的 actor+critic 系统,并且在推理时会对生成的推理步骤进行搜索或回溯。
测试时计算
o1 的一个最重要特性就是展示了如何将连锁推理搜索应用于非形式化语言,而非数学、编程或 Lean 这样格式化的语言。
虽然训练时的扩展使用连锁推理是值得注意的,但测试时的扩展才是最大的亮点。
我们认为迭代连锁推理确实解锁了更大的泛化能力。自动化的迭代重提示能够让模型更好地适应新情况,这与 MindsAI 团队利用测试时微调的方式类似。
如果我们只进行一次推理,我们被限制在重新应用记忆化的程序。然而,通过为每个任务生成中间输出连锁推理或程序,我们解锁了组合学习程序组件的能力,从而实现适应性。这种技术是一种解决大规模语言模型泛化的首要问题——适应新情况的方法。
当人工智能系统在测试时允许可变的计算量(例如推理步骤的数量或搜索时间)时,就没有客观的方法来报告单一的基准分数,因为它与允许的计算量相关。这也正是以下图表所展示的内容。
更多的计算意味着更高的准确性
当 OpenAI 发布 o1 时,他们本可以允许开发者指定在测试时用于优化连锁推理的计算量或时间。相反,他们在测试时的计算连续范围内“硬编码”了一个点,并隐藏了这一实现细节。
有了变化的测试时计算量后,我们就不能仅仅比较两个 AI 系统的输出,以评估相对智能水平。我们还需要比较其计算效率。
虽然 OpenAI 的声明中没有分享效率数据,但令人兴奋的是,我们正进入一个以效率为重点的时期。效率对于 AGI 的定义至关重要,这也是为什么 ARC 奖项对获胜解决方案设置了效率限制。
我们的预测是:今后你会看到更多比较准确性与测试时计算的基准图表。
ARC-AGI-Pub 模型基线
在ARC-AGI公共评估数据集上,OpenAI 的 o1-preview 和 o1-mini 都优于 GPT-4o。o1-preview 的准确性与Anthropic的 Claude 3.5 Sonnet 相当,但需要更长的时间才能达到类似的结果。
| 模型 | 公共评估分数 | 半私密评估中的验证分数 | 每任务平均时间(分钟) |
|---|---|---|---|
| o1-preview | 21.2% | 18% | 4.2 |
| Claude 3.5 | 21% | 14% | 0.3 |
| o1-mini | 12.8% | 9.5% | 3.0 |
| GPT-4o | 9% | 5% | 0.3 |
| Gemini 1.5 | 8% | 4.5% | 1.1 |
为了在 ARC-AGI-Pub 排行榜上获得基线模型评分,我们使用了与测试 GPT-4o 相同的基线提示。测试和报告类似模型的结果时,我们的目的是尽可能地测量基模型的性能,而不进行任何优化层。
我们欢迎其他人在未来发现更好的方法来提示连锁推理模型,并在验证后加入排行榜。
o1 的性能提升确实付出了时间成本。处理400个公共任务耗时70小时,而 GPT-4o 和 Claude 3.5 Sonnet 仅需30分钟。
你可以使用我们的开源 Kaggle 笔记本作为基线测试工具或自己方法的起点。公共排行榜上的最优提交结果是巧妙的技术和尖端模型的结合。
也许你能找到如何利用 o1 作为基础组件,达到更高分数的方法!
AGI 到来了?
在这张图表中,OpenAI 展示了在 AIME 上准确性和测试时计算量之间的对数线性关系。换句话说,随着计算量的指数增长,准确性线性提高。
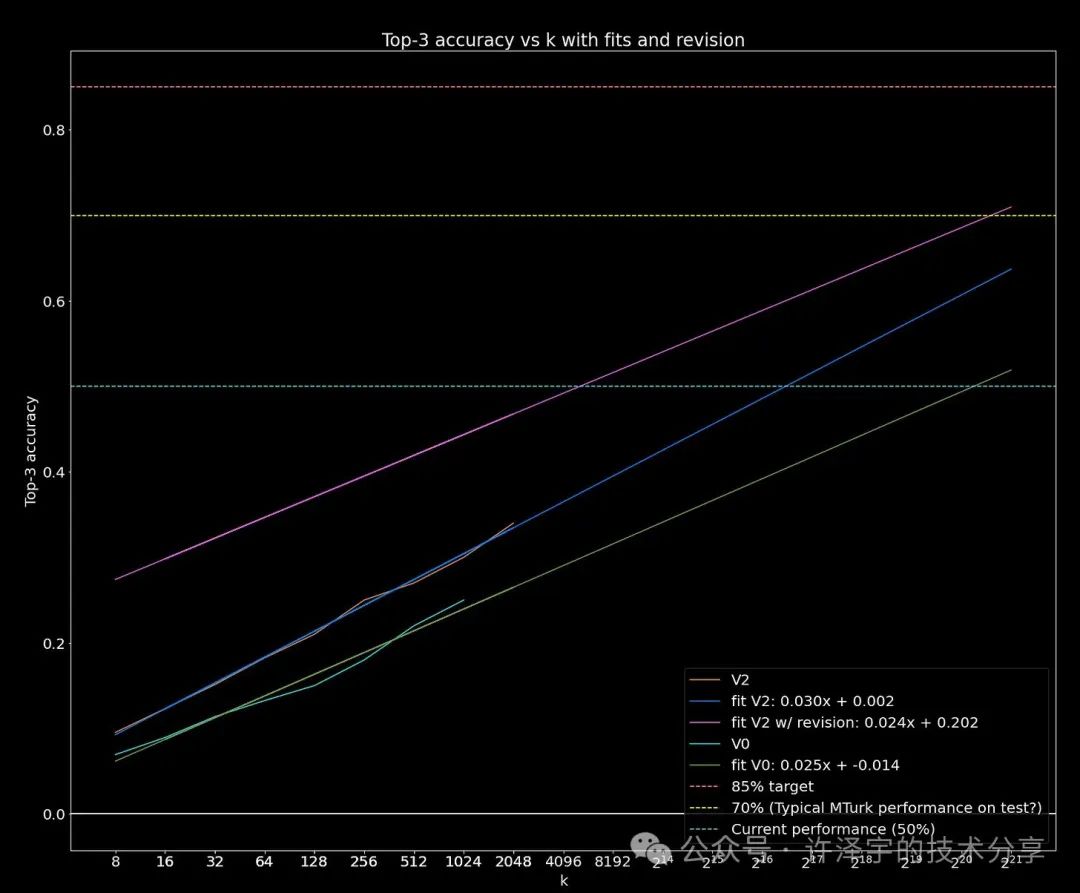
来源:Ryan Greenblatt
许多人在问:这种方法可以扩展到多远?
这种方法的唯一概念限制是所提出问题的可判定性。只要搜索过程有一个包含答案的外部验证器,你会看到准确性随着计算量的对数关系扩展。
实际上, 报告的结果非常类似于 Ryan Greenblatt 在 ARC 奖项中的顶尖方法之一。他通过让 GPT-4o 每个任务生成 k=2,048 个解决方案程序并通过任务演示进行确定性验证,达到了43%的得分。
然后他评估了不同 k 值时的准确性变化。
这种对数线性关系是否意味着只要扩大测试时计算量,AGI 就能到来?并不完全是。
通过观察任何 O(x^n) 的暴力搜索,你也会看到类似的指数扩展曲线。实际上,我们知道至少50%的 ARC-AGI 可以通过暴力搜索和零 AI 方法解决。
为了以这种方式击败 ARC-AGI,你需要为每个任务生成超过一亿个解决方案程序。仅从实用性来看,O(x^n) 搜索对于扩展的 AI 系统已经被排除。
此外,我们知道人类并不是通过生成成千上万个潜在解决方案来击败 ARC 任务。人类使用大脑中的感知网络“看到”少量潜在解决方案,并用系统 2 式的思维进行确定性检查。
我们可以变得更聪明。
新的思想是必需的
可以通过观察系统如何在各种情境下将信息转换为行动来衡量其智能。这是一个转换率,因而趋近于一个极限。一旦达到完美的智能,唯一的进步方式就是收集新信息。
低智系统可以通过不同方式显得更加智能,但实际上并没有提高智能。
一种方法是系统仅仅记住最佳行动。这种系统会非常脆弱,在一个领域显得聪明,但在另一个领域却容易崩溃。
另一种方法是通过试错法。如果一个系统最终能得到正确答案,但需要100次尝试,这种系统也会显得不那么智能。
我们应该期待未来的测试时计算研究,朝着更高效地扩展搜索和优化的方向迈进,或许可以使用深度学习来指导搜索过程。
尽管如此,我们不相信这完全解释了 o1 在 ARC-AGI 上与其他客观困难基准(如 IOI 或 AIME)之间的巨大差异。
更合理的解释是,o1 仍然主要在其预训练数据的分布内运作,但现在包括了所有新生成的合成连锁推理数据。
额外的合成连锁推理数据增加了在解答分布上的关注,而不仅仅是答案分布(更多计算量花费在了如何得到答案上而不是答案是什么)。我们预计像 o1 这样的系统在使用已知模拟推理模板(程序)时表现会更好,但在需要即时生成全新推理的问题上仍会困难重重。
测试时的连锁推理优化只能修正到一定限度的推理错误。这也解释了为什么 o1 在某些领域如此令人印象深刻。当基础模型以类似方式预训练时,测试时的连锁推理优化会得到额外的提升。
单凭任何一种方法,并不会带来飞跃性的进步。
综上所述,o1 代表了一种从“记住答案”到“记住推理”的范式转变,但并没有脱离通过拟合分布曲线来提升性能的广泛范式。
我们仍然需要新的想法来实现AGI。







网友评论