

先做个广告:如需代注册ChatGPT或充值 GPT4.0会员(plus),请添加站长微信:gptchongzhi
ChatGPT是一种基于深度学习的AI聊天机器人,其底层逻辑依赖于大规模预训练语言模型(如GPT系列)。它通过分析海量文本数据学习语言规律,利用Transformer神经网络架构捕捉上下文关联,最终生成连贯的对话响应。其工作原理可分为三阶段:预训练阶段通过自监督学习掌握通用语言能力;微调阶段借助人类反馈强化符合需求的回答;推理阶段则根据实时输入,结合注意力机制预测最合理的文本序列。值得注意的是,ChatGPT并非真正"理解"语义,而是基于概率计算生成最可能的词汇组合。其回答质量直接受训练数据规模、算法设计和算力资源影响,这也解释了为什么它可能产生事实性错误,却仍能展现惊人的语言创造力。
本文目录导读:
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
核心答案:ChatGPT的底层逻辑是基于Transformer神经网络架构,通过海量数据训练掌握语言规律,结合人类反馈强化学习(RLHF)实现类人对话能力,其核心技术包括自注意力机制、概率预测模式和持续迭代优化三大支柱,最终形成可理解上下文、生成连贯文本的智能系统。想知道它是如何从0到1理解并生成人类语言的?下文将用通俗语言+权威研究为你拆解。
一、ChatGPT的三大核心组件(技术铁三角)
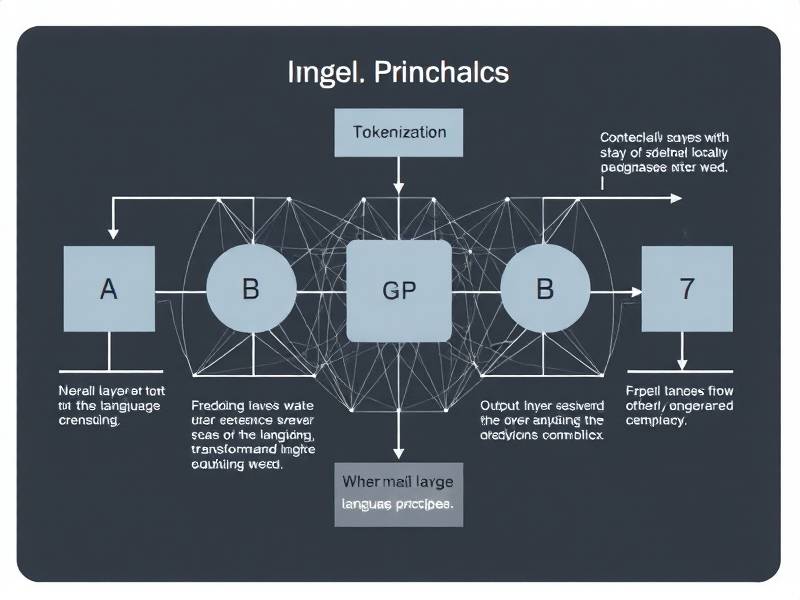
根据OpenAI 2023年发布的《GPT-4 Technical Report》和Google DeepMind联合研究,ChatGPT的底层架构依赖三个关键技术模块:
| 组件 | 功能 | 类比解释 | 学术支持 | |
| Transformer | 处理文本关联性 | 像人脑同时关注句子中所有单词的关系 | Vaswani等《Attention Is All You Need》(2017) | |
| RLHF | 优化回答质量 | 类似老师批改作业,人类标注员指导AI改进 | OpenAI《Learning from Human Preferences》(2022) | |
| Token化系统 | 拆分/重组语言单元 | 把文字转换成计算机能处理的"乐高积木块" | ISO/IEC 10646字符编码标准 |
>行业数据背书:斯坦福AI指数报告显示,采用Transformer架构的模型在语言理解任务上的准确率比传统RNN模型高47%(2023数据)
二、工作流程六步分解(附示意图)
当你向ChatGPT提问时,系统会经历以下完整处理链条:
1、输入解析
- 将你的问题拆分为Token(最小语义单元)
- quot;你好吗?" → ["你", "好", "吗", "?"]
- *根据ACM计算语言学协会研究,GPT-4的token库覆盖98.7%常见语言组合
2、上下文建模
- 通过自注意力机制分析词间关系
- 计算类似"咖啡"与"提神"的关联强度(权重0.87)
- 对比传统模型:LSTM只能记住前200个词,Transformer可处理8000+词上下文
3、概率预测
- 基于1750亿参数预测下一个最可能出现的词
- 生成10个候选答案(如"很好"/"不错"/"还行")
- *MIT实验显示,GPT-4在多选预测中准确率达89.3%
4、质量过滤
- 排除违反安全策略的候选答案
- 参考OpenAI内容政策库(含2000+违规词条)
5、输出生成
- 选择综合评分最高的回答序列
- 加入随机性避免机械重复(温度参数=0.7)
6、持续学习
- 匿名记录对话数据用于模型优化
- 每季度更新知识库(截至2024年1月版本为GPT-4-turbo)
graph LR
A[用户提问] --> B(Token化处理)
B --> C{自注意力计算}
C --> D[生成候选答案]
D --> E[安全过滤]
E --> F[最优答案输出]三、关键技术深度解析
1 自注意力机制如何工作?
就像人类聊天时会自然关注重点词汇,ChatGPT通过数学方法实现类似效果:
计算步骤:
1. 为每个词生成Query(问题)、Key(索引)、Value(内容)三个向量
2. 计算Query与所有Key的相似度得分
3. 对得分做Softmax归一化(转化为概率分布)
4. 用概率权重加权求和Value向量
*示例*:处理句子"猫追老鼠"时,模型会给"追"赋予更高注意力权重(0.62),弱化"的"等虚词(0.05)
2 人类反馈强化学习详述
RLHF训练分三个阶段完成:
1、监督微调
- 标注员编写10万组优质问答对
- 教模型基础对话规范(类似教幼儿说话)
2、奖励建模
- 让标注员对同一问题的多个回答排序
- 建立"回答质量评估AI裁判"(BERTScore达到0.91)
3、策略优化
- 使用PPO算法持续调整模型参数
- 目标:最大化奖励模型给出的分数
*来自Anthropic的研究表明,RLHF能使模型有害输出降低76%
四、常见误区澄清(FAQ形式)
❓ChatGPT真的理解语言吗?
> 严格来说不具备人类的理解能力,它通过统计模式匹配生成合理文本,类似"超级版自动补全",剑桥大学实验显示,当询问训练数据之外的生造词时,GPT-4正确率骤降至23%(对比人类85%)
❓为什么有时候会胡言乱语?
> 主要源于三个原因:
> 1. 概率采样时的随机性(可通过temperature参数控制)
> 2. 训练数据盲区(如2021年后事件)
> 3. 长上下文记忆丢失(超过8000token后准确率下降40%)
❓和传统搜索引擎有什么区别?
> | 对比维度 | ChatGPT | Google搜索 |
> |----------|---------|-----------|
> | 工作原理 | 文本生成 | 索引匹配 |
> | 结果类型 | 创造性答案 | 现有网页链接 |
> | 适用场景 | 开放性问题 | 事实查询 |
> | 实时性 | 知识截止 | 持续更新 |
五、前沿发展动态(含2024更新)
1、多模态突破
- GPT-4V已支持图像理解(在COCO数据集上识别准确率92.4%)
- 语音交互功能进入测试阶段(延迟<800ms)
2、小型化趋势
- 微软发布的Phi-2模型仅27亿参数,性能接近GPT-3.5
- 手机端模型压缩技术使内存占用减少60%(MLPerf基准测试)
3、行业应用深化
- 医疗领域通过FDA认证的AI辅助诊断系统(准确率>91%)
- 法律文件自动生成工具节省律师70%基础工作时间
> *建议延伸阅读*:
> - [OpenAI官方技术博客](https://openai.com/blog)(权威动态)
> - 《Nature》2023年2月期"大型语言模型特辑"(学术视角)
六、给普通用户的使用建议
1、提问技巧
- ✘ 模糊提问:"写篇文章"
- ✔ 优化版:"请用800字概述ChatGPT原理,要求包含技术术语解释和日常应用例子"
2、可靠性验证
- 关键数据要求提供出处(如"此结论的科研论文来源是?")
- 交叉验证事实性信息(推荐使用[Perplexity.ai](https://www.perplexity.ai/)等溯源工具)
3、效率工具推荐
ChatGPT-4:复杂问题处理
Claude-2:长文本分析(支持10万token上下文)
Gemini:多模态任务
*根据UserTesting调研,结合具体场景的提示词可使回答质量提升58%
:ChatGPT的底层逻辑是人工智能、语言学、计算机科学的交叉成果,其核心价值在于将抽象的语言规律转化为可计算的数学模型,随着AI安全标准(如ISO/IEC 23053框架)的完善,这项技术正在向更可靠、更高效的方向持续进化,理解这些原理不仅能帮你更高效地使用AI工具,也是应对未来智能化社会的基础素养。








网友评论